Spark interview question part-1
1. What is Apache Spark and what are the benefits of Spark over MapReduce?
2. Is there any point of learning MapReduce, then?
3. What are the downsides of Spark?
Spark utilizes the memory. So, in a shared environment, it might consume little more memory for longer durations.
The developer has to be careful. A casual developer might make following mistakes:
The first problem is well tackled by Hadoop MapReduce paradigm as it ensures that the data your code is churning is fairly small a point of time thus you can make a mistake of trying to handle whole data on a single node.
The second mistake is possible in MapReduce too. While writing MapReduce, a user may hit a service from inside of map()or reduce() too many times. This overloading of service is also possible while using Spark.
4. Explain in brief what is the architecture of Spark?
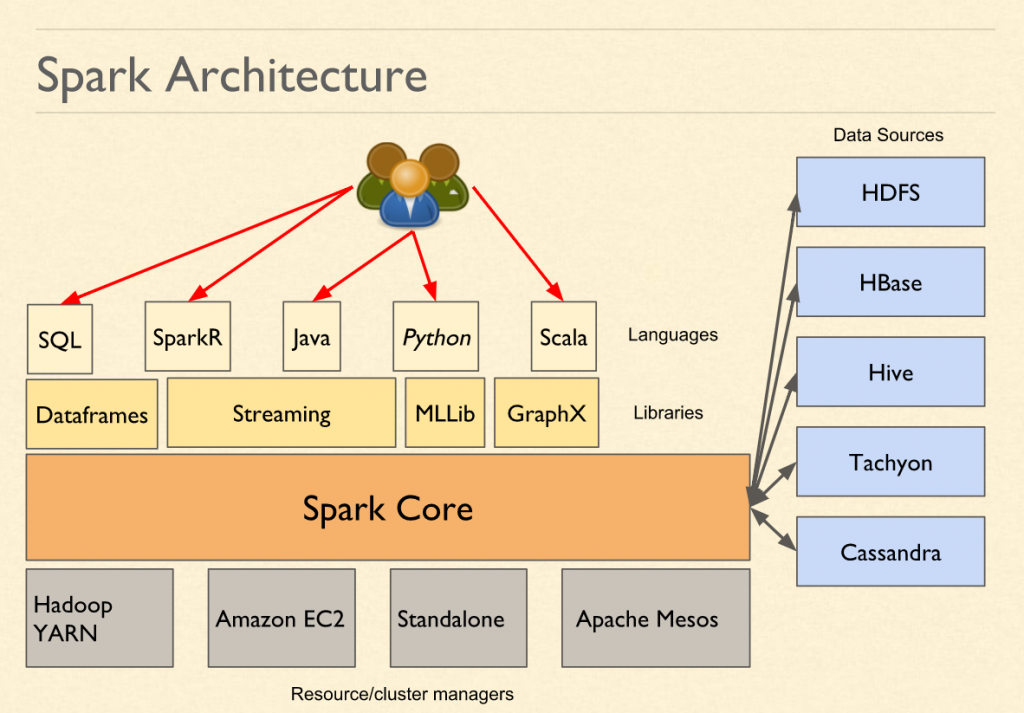
At the architecture level, from a macro perspective, the Spark might look like this:
Spark Architecture
| 5) Interactive Shells or Job Submission Layer |
| 4) API Binding: Python, Java, Scala, R, SQL |
| 3) Libraries: MLLib, GraphX, Spark Streaming |
| 2) Spark Core (RDD & Operations on it) |
| 1) Spark Driver -> Executor |
| 0) Scheduler or Resource Manager |
0) Scheduler or Resource Manager:
At the bottom is the resource manager. This resource manager could be external such YARN or Mesos. Or it could be internal if the Spark is running in standalone mode. The role of this layer is to provide a playground in which the program can run distributively. For example, YARN (Yet Another Resource Manager) would create application master, executors for any process.
1) Spark Driver -> Executor:
One level above scheduler is the actual code by the Spark which talks to the scheduler to execute. This piece of code does the real work of execution. The Spark Driver that would run inside the application master is part of this layer. Spark Driver dictates what to execute and executor executes the logic.
2) Spark Core (RDD & Operations on it):
Spark Core is the layer which provides maximum functionality. This layer provides abstract concepts such as RDD and the execution of the transformation and actions.
3) Libraries: MLLib,, GraphX, Spark Streaming, Dataframes:
The additional vertical wise functionalities on top of Spark Core is provided by various libraries such as MLLib, Spark Streaming, GraphX, Dataframes or SparkSQL etc.
4) API Bindings are internally calling the same API from different languages.
5) Interactive Shells or Job Submission Layer:
The job submission APIs provide a way to submit bundled code. It also provides interactive programs (PySpark, SparkR etc.) that are also called REPL or Read-Eval-Print-Loop to process data interactively.
5. On which all platform can Apache Spark run?
Spark can run on the following platforms:
6. What are the various programming languages supported by Spark?
Though Spark is written in Scala, it lets the users code in various languages such as:
Also, by the way of piping the data via other commands, we should be able to use all kinds of programming languages or binaries.
7. What are the various modes in which Spark runs on YARN? (Local vs Client vs Cluster Mode)
Apache Spark has two basic parts:
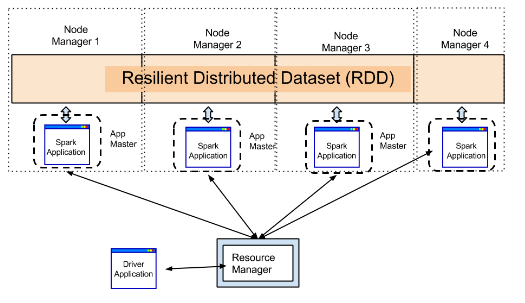
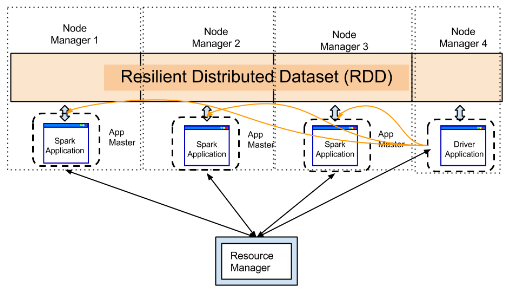
While running Spark on YARN, though it is very obvious that executor will run inside containers, the driver could be run either on the machine which user is using or inside one of the containers. The first one is known as Yarn client mode while second is known as Cluster-Mode. The following diagrams should give you a good idea:
YARN client mode: The driver is running on the machine from which client is connected
YARN cluster mode: The driver runs inside the cluster.
 Local mode: It is only for the case when you do not want to use a cluster and instead want to run everything on a single machine. So Driver Application and Spark Application are both on the same machine as the user.
Local mode: It is only for the case when you do not want to use a cluster and instead want to run everything on a single machine. So Driver Application and Spark Application are both on the same machine as the user.8. What are the various storages from which Spark can read data?
Spark has been designed to process data from various sources. So, whether you want to process data stored in HDFS, Cassandra, EC2, Hive, HBase, and Alluxio (previously Tachyon). Also, it can read data from any system that supports any Hadoop data source.
9. While processing data from HDFS, does it execute code near data?
Yes, it does in most cases. It creates the executors near the nodes that contain data.
10. What are the various libraries available on top of Apache Spark?


Comments
Post a Comment