Spark interview question part-4
1. What does reduce action do?
A reduce action converts an RDD to a single value by applying recursively the provided (in argument) function on the elements of an RDD until only one value is left. The provided function must be commutative and associative – the order of arguments or in what way we apply the function should not make difference.
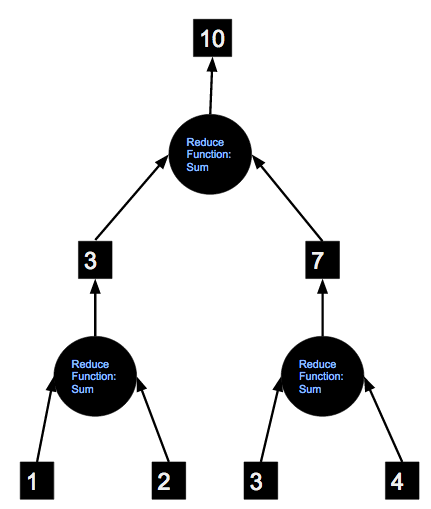
The following diagram shows the process of applying “sum” reduce function on an RDD containing 1, 2, 3, 4.
2. What is broadcast variable?
Quite often we have to send certain data such as a machine learning model to every node. The most efficient way of sending the data to all of the nodes is by the use of broadcast variables.
Even though you could refer an internal variable which will get copied everywhere but the broadcast variable is far more efficient. It would be loaded into the memory on the nodes only where it is required and when it is required not all the time.
It is sort of a read-only cache similar to distributed cache provided by Hadoop MapReduce.
3. What is accumulator?
An accumulator is a good way to continuously gather data from a Spark process such as the progress of an application. The accumulator receives data from all the nodes in parallel efficiently. Therefore, only the operations in order of operands don’t matter are valid accumulators. Such functions are generally known as associative operations.
An accumulator a kind of central variable to which every node can emit data.
4. Say I have a huge list of numbers in RDD(say myRDD). And I wrote the following code to compute average:
def myAvg(x, y):
return (x+y)/2.0;
avg = myrdd.reduce(myAvg);What is wrong with it and how would you correct it?
The average function is not commutative and associative. I would simply sum it and then divide by count.
def sum(x, y):
return x+y;
total = myrdd.reduce(sum);
avg = total / myrdd.count();The only problem with the above code is that the total might become very big thus overflow. So, I would rather divide each number by count and then sum in the following way.
cnt = myrdd.count();
def devideByCnd(x):
return x/cnt;
myrdd1 = myrdd.map(devideByCnd);
avg = myrdd.reduce(sum);The problem with above code is that it uses two jobs – one for the count and other for the sum. We can do it in a single shot as follows:
myrdd = sc.parallelize([1.1, 2.4, 5, 6.0, 2, 3, 7, 9, 11, 13, 10]) sumcount_rdd = myrdd.map(lambda n : (n, 1)) (total, counts) = sumcount_rdd.reduce(lambda a,b: (a[0]+b[0], a[1]+b[1])) avg = total/counts
Again, it might cause a number overflow because we are summing a huge number of values. We could instead keep the average values and keep computing the average from the average and counts of two parts getting reduced.
myrdd = sc.parallelize([1.1, 2.4, 5, 6.0, 2, 3, 7, 9, 11, 13, 10])
sumcount_rdd = myrdd.map(lambda n : (n, 1))
def avg(A, B):
R = 1.0*B[1]/A[1]
Ri = 1.0/(1+R);
av = A[0]*Ri + B[0]*R*Ri
return (av, B[1] + A[1]);
(av, counts) = sumcount_rdd.reduce(avg)
print(av)If you have two parts having average and counts as (a1, c1) and (a2, c2), the overall average is:
total/counts = (total1 + total2)/ (count1 + counts2) = (a1*c1 + a2*c2)/(c1+c2)
If we mark R = c2/c1, It can be re-written further as a1/(1+R) + a2*R/(1+R)
If we further mark Ri as 1/(1+R), we can write it as a1*Ri + a2*R*Ri
5. Say I have a huge list of numbers in a file in HDFS. Each line has one number and I want to compute the square root of the sum of squares of these numbers. How would you do it?
# We would first load the file as RDD from HDFS on Spark
numsAsText = sc.textFile("hdfs:////user/student/sgiri/mynumbersfile.txt");# Define the function to compute the squares
def toSqInt(str):
v = int(str);
return v*v;#Run the function on Spark rdd as transformation nums = numsAsText.map(toSqInt); #Run the summation as reduce action total = nums.reduce(sum) #finally compute the square root. For which we need to import math. import math; print math.sqrt(total);
6. Is the following approach correct? Is the sqrtOfSumOfSq a valid reducer?
numsAsText = sc.textFile("hdfs:///user/student/sgiri/mynumbersfile.txt");
def toInt(str):
return int(str);
nums = numsAsText.map(toInt);
def sqrtOfSumOfSq(x, y):
return math.sqrt(x*x+y*y);
total = nums.reduce(sum)
import math;
print math.sqrt(total);
Yes. The approach is correct and sqrtOfSumOfSq is a valid reducer.
7. In a very huge text file, you want to just check if a particular keyword exists. How would you do this using Spark?
lines = sc.textFile("hdfs:///user/student/sgiri/bigtextfile.txt");
def isFound(line):
if line.find("mykeyword") > -1:
return 1;
return 0;
foundBits = lines.map(isFound);
sum = foundBits.reduce(sum);
if sum > 0:
print “FOUND”;
else:
print “NOT FOUND”;8. Can you improve the performance of the code in the previous answer?
Yes. The search is not stopping even after the word we are looking for has been found. Our map code would keep executing on all the nodes which is very inefficient.
We could utilize accumulators to report whether the word has been found or not and then stop the job. Something on these lines.
import thread, threading
from time import sleep
result = "Not Set"
lock = threading.Lock()
accum = sc.accumulator(0)
def map_func(line):
#introduce delay to emulate the slowness
sleep(1);
if line.find("Adventures") > -1:
accum.add(1);
return 1;
return 0;
def start_job():
global result
try:
sc.setJobGroup("job_to_cancel", "some description")
lines = sc.textFile("hdfs:///user/student/sgiri/wordcount/input/big.txt");
result = lines.map(map_func);
result.take(1);
except Exception as e:
result = "Cancelled"
lock.release()
def stop_job():
while accum.value < 3 :
sleep(1);
sc.cancelJobGroup("job_to_cancel")
supress = lock.acquire()
supress = thread.start_new_thread(start_job, tuple())
supress = thread.start_new_thread(stop_job, tuple())
supress = lock.acquire()


Comments
Post a Comment