Spark interview question part-2
1. Does Spark provide the storage layer too?
No, it doesn’t provide storage layer but it lets you use many data sources. It provides the ability to read from almost every popular file systems such as HDFS, Cassandra, Hive, HBase, SQL servers.
2. Where does Spark Driver run on Yarn?
If you are submitting a job with –master client, the Spark driver runs on the client’s machine. If you are submitting a job with –master yarn-cluster, the Spark driver would run inside a YARN container.
3. To use Spark on an existing Hadoop Cluster, do we need to install Spark on all nodes of Hadoop?
Since Spark runs as an application on top of Yarn, it utilizes yarn for the execution of its commands over the cluster’s nodes. So, you do not need to install the Spark on all nodes. When a job is submitted, the Spark will be installed temporarily on all nodes on which execution is needed.
4. What is sparkContext?
SparkContext is the entry point to Spark. Using sparkContext you create RDDs which provided various ways of churning data.
5. What is DAG – Directed Acyclic Graph?
Directed Acyclic Graph – DAG is a graph data structure having edges which are directional and do not have any loops or cycles.
People use DAG almost all the time. Let’s take an example of getting ready for office.
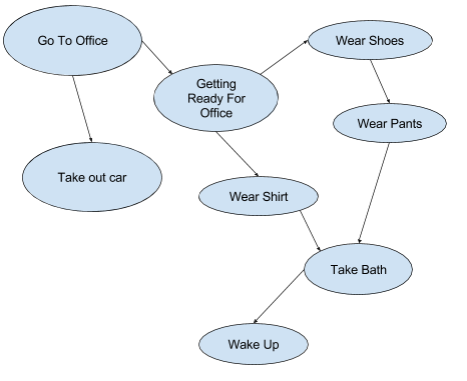
DAG is a way of representing dependencies between objects. It is widely used in computing. The examples where it is used in computing are:
6. What is an RDD?
The full form of RDD is a resilient distributed dataset. It is a representation of data located on a network which is
You can always think of RDD as a big array which is under the hood spread over many computers which are completely abstracted. So, RDD is made up many partitions each partition on different computers.
RDD provides two kinds of operations: Transformations and Actions.
RDD can hold data of any type from any supported programming language such as Python, Java, Scala. The case where RDD’s each element is a tuple – made up of (key, value) is called Pair RDD. PairRDDs provides extra functionalities such as “group by” and joins.
RDD is generally lazily computed i.e. it is not computed unless an action on it is called. So, RDD is either prepared out of another RDD or it is loaded from a data source. In case, it is loaded from another data source it has a binding between the actual data storage and partitions. So, RDD is essentially a pointer to actual data, not data unless it is cached.
If a machine that holds a partition of RDD dies, the same partition is regenerated using the lineage graph of RDD.
If there is a certain RDD that you require very frequently, you can cache it so that it is readily available instead of re-computation every time. Please note that the cached RDD will be available only during the lifetime of the application. If it is costly to recreate the RDD every time, you may want to persist it to the disc.
RDD can be stored at various data storage (such as HDFS, database etc.) in many formats.
7. What is lazy evaluation and how is it useful?
Imagine there are two restaurants I (immediate) and P (patient).
In a restaurant I, the waiters are very prompt – as soon as you utter the order they run to the kitchen and place an order to the chef. If you have to order multiple things, the waiter will make multiple trips to the kitchen.
In P, the waiter patiently hears your orders and once you confirm your orders they go to the chef and place the orders. The waiter might combiner multiple dishes into one and prepare. This could lead to tremendous optimization.
While in the restaurant I, the work appears to happen immediately, in restaurant P the work would be actually fast because of clubbing multiple items together for preparation and serving. Restaurant P is doing we call ‘Lazy Evaluation’.
Examples of lazy evaluations are Spark, Pig (Pig Latin). The example of immediate execution could be Python interactive shell, SQL etc.
8. How to create an RDD?
You can create an RDD from an in-memory data or from a data source such as HDFS.
You can load the data from memory using parallelize method of Spark Context in the following manner, in python:
myrdd = sc.parallelize([1,2,3,4,5]);
Here myrdd is the variable that represents an RDD created out of an in-memory object. “sc” is the sparkContext which is readily available if you are running in interactive mode using PySpark. Otherwise, you will have to import the SparkContext and initialize.
And to create RDD from a file in HDFS, use the following:
linesrdd = sc.textFile("/data/file_hdfs.txt");This would create linesrdd by loading a file from HDFS. Please note that this will work only if your Spark is running on top of Yarn. In case, you want to load the data from external HDFS cluster, you might have to specify the protocol and name node:
linesrdd = sc.textFile("hdfs://namenode_host/data/file_hdfs.txt");In the similar fashion, you can load data from third-party systems.
9. When we create an RDD, does it bring the data and load it into the memory?
No. An RDD is made up of partitions which are located on multiple machines. The partition is only kept in memory if the data is being loaded from memory or the RDD has been cached/persisted into the memory. Otherwise, an RDD is just mapping of actual data and partitions.
10. If there is certain data that we want to use again and again in different transformations, what should improve the performance?
RDD can be persisted or cached. There are various ways in which it can be persisted: in-memory, on disc etc. So, if there is a dataset that needs a good amount computing to arrive at, you should consider caching it. You can cache it to disc if preparing it again is far costlier than just reading from disc or it is very huge in size and would not fit in the RAM. You can cache it to memory if it can fit into the memory.



Comments
Post a Comment