Spark interview question part-3
1. What happens to RDD when one of the nodes on which it is distributed goes down?
Since Spark knows how to prepare a certain data set because it is aware of various transformations and actions that have lead to the dataset, it will be able to apply the same transformations and actions to prepare the lost partition of the node which has gone down.
2. How to save RDD?
There are few methods provided by Spark:
3. What do we mean by Paraquet?
Apache Paraquet is a columnar format for storage of data available in Hadoop ecosystem. It is space efficient storage format which can be used in any programming language and framework.
Apache Spark supports reading and writing data in Paraquet format.
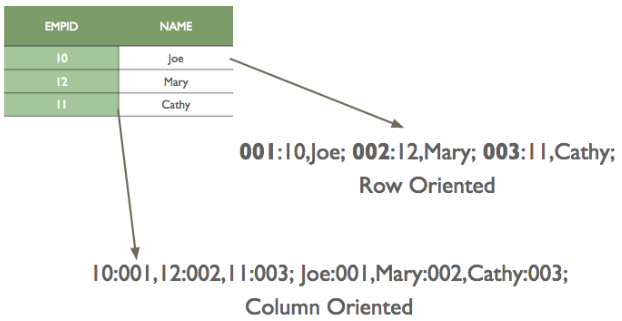
4. What does it mean by Columnar Storage Format?
While converting a tabular or structured data into the stream of bytes we can either store row-wise or we could store column-wise.
In row-wise, we first store the first row and then store the second row and so on. In column-wise, we first store first column and second column.
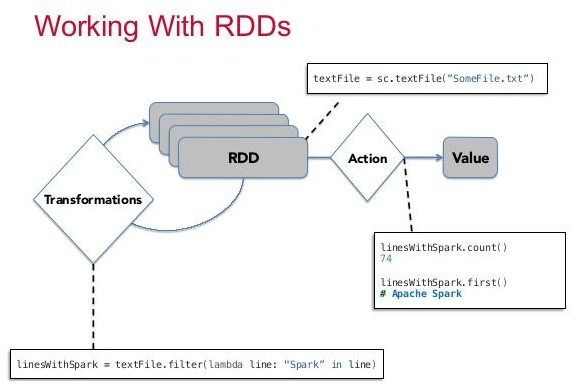
5. When creating an RDD, what goes on internally?
There are two ways to create RDD. One while loading data from a source. Second, by operating on existing RDD. And an action causes the computation from an RDD to yield the result. The diagram below shows the relationship between RDD, transformations, actions and value/result.
6. What do we mean by Partitions or slices?
Partitions (also known as slices earlier) are the parts of RDD. Each partition is generally located on a different machine. Spark runs a task for each partition during the computation.
If you are loading data from HDFS using textFile(), it would create one partition per block of HDFS(64MB typically). Though you can change the number of partitions by specifying the second argument in the textFile() function.
If you are loading data from an existing memory using sc.parallelize(), you can enforce your number of partitions by passing the second argument.
You can change the number of partitions later using repartition().
If you want certain operations to consume the whole partitions at a time, you can use map partition().
7. What is meant by Transformation? Give some examples.
The transformations are the functions that are applied on an RDD (resilient distributed dataset). The transformation results in another RDD. A transformation is not executed until an action follows.
Some examples of transformation are:
8. What does map transformation do? Provide an example.
Map transformation on an RDD produces another RDD by translating each element. It translates each element by executing the function provided by the user.
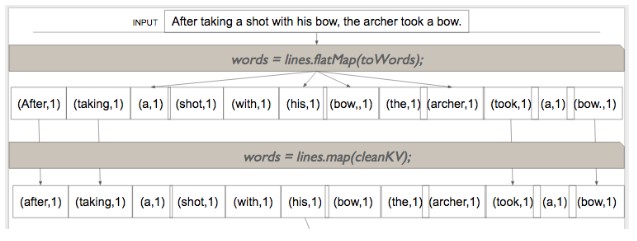
9. What is the difference between map and flatMap?
Map and flatMap both functions are applied to each element of RDD. The only difference is that the function that is applied as part of the map must return only one value while flatMap can return a list of values.So, flatMap can convert one element into multiple elements of RDD while map can only result in an equal number of elements.
So, flatMap can convert one element into multiple elements of RDD while map can only result in an equal number of elements.
So, if we are loading RDD from a text file, each element is a sentence. To convert this RDD into an RDD of words, we will have to apply using flatMap a function that would split a string into an array of words. If we have just to clean up each sentence or change case of each sentence, we would be using the map instead of flatMap. See the diagram below.
10. What are Actions? Give some examples.
An action brings back the data from the RDD to the local machine. Execution of an action results in all the previously created transformation. The example of actions are:



Comments
Post a Comment