SPARK - Optimization Techniques
Apache Spark is a well known Big Data Processing Engine out in market right now. It helps in lots of use cases, right from real time processing (Spark Streaming) till Graph processing (GraphX). As an organization, investment on Spark technology has become an inevitable move. The craze for the adoption is due to two major factors,
- Big community and good integration with other well known projects
- Ease of use (APIs are pretty simple and elegant to use)
Optimizations
Lets jump to the optimizations,
- Narrow transformations than Wide transformations
- Use columnar data formats for structured data
- Partition the data at Source for better overall performance
- Converting Dataframe to RDD is expensive — avoid it at all costs
- Use broadcast hint for all smaller table joins
- Use well informed Spark Config Parameters for your program
Narrow transformations than Wide transformations
Shuffling means moving the data across the partitions — sometimes across the nodes as well which causes data movement through the network
Narrow transformations are the result of map(), filter() functions and these compute data that live on a single partition meaning there will not be any data movement between partitions to execute narrow transformations
Whereas, Wider transformations are the result of groupByKey() and reduceByKey()functions and these compute data that live on many partitions meaning there will be data movements between partitions to execute wider transformations
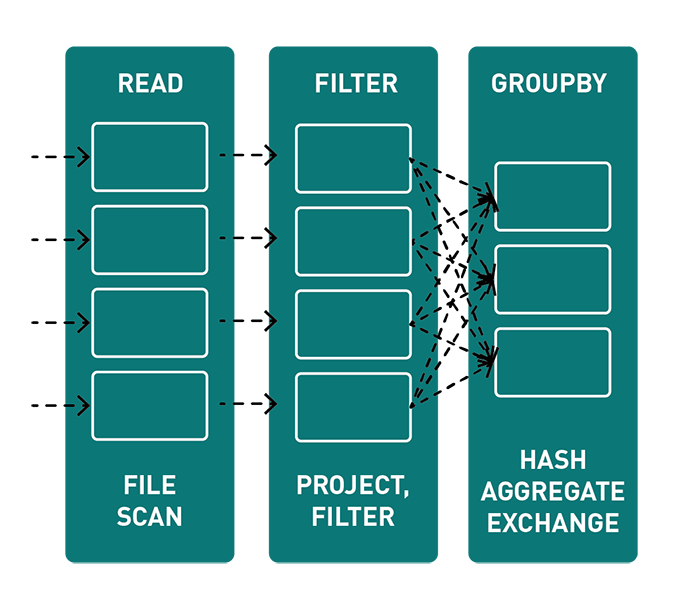
Performing the narrow transformations are quite fast since the data resides on same partition. Hence, try to perform most of the narrow transformations before a wider transformations (shuffling)
Use columnar data formats for structured data
Spark Dataframes are similar to tables in RDBMS. It contains the schema of the data which helps catalyst optimiser to know the exact size of the data which in turn helps in performing computations on specific column rather than reading the complete row
Columnar formats such as Parquet, ORC etc. provides an additional optimization of pushing the filters down to files rather than loading the complete data in-memory then selecting only desired columns
Partition the data at Source for better overall performance
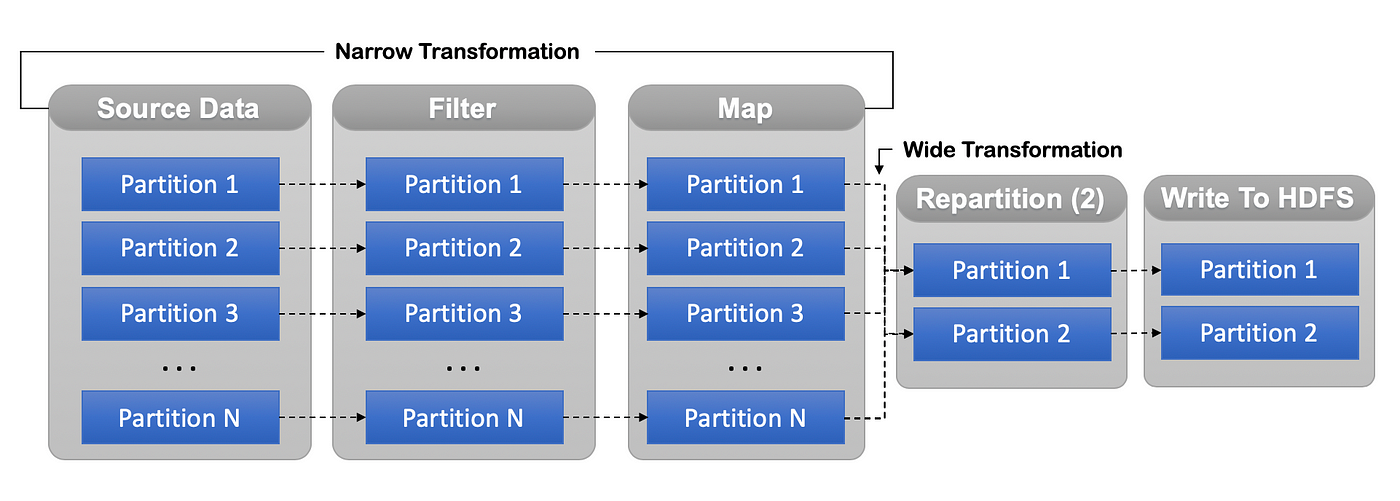
Number of data partitions present at source is the number of tasks spark executes in parallel. Unless we explicitly perform a repartition(), coalesce() or any wider transformations, no.of parallel tasks will not be changed. This will help in moving the processing closer to the smaller sized data and perform the tasks faster rather than on one big dataset
Based on the domain of your data and your usage — partition the data for better querying and processing. Sometimes repartition (or) coalesce is inevitable if the data is skewed after certain transformations like filtering some pattern of data. In an example below, Before we write to HDFS — we perform repartition which makes all the operations faster since no data is shuffled — and to make write efficient in storage we perform repartition. Make sure to perform repartition at a stage in your DAG where it’s efficient for further processing.
Converting Dataframe to RDD is expensive — avoid it at all costs
There is an option to convert a Dataframe to RDD and perform processing on top of it. But this operation is expensive and avoid it at all costs!!
Use broadcast hint for all smaller table joins
Broadcast join can be very efficient for joins between a large table (fact) with relatively small tables (dimensions) that could then be used to perform a star-schema join. It can avoid sending all data of the large table over the network
This will help in transferring the table to executors rather than shuffling the data for joining which will enhance the overall execution cost
Use well informed Spark Config Parameters for your program
spark configuration is the main culprit most of the time while we perform any optimizations. If the configuration is bad — even the most efficient code can slow down the execution.
For an example, if we have an huge data — with 200 partitions. If each partition amounts to a size of 10G.
Now, if we configure --executor-memory 2Gthen each partition will not fit in memory — which will end up in lots of GC over the course of execution. Hence, the spark configuration is quite an important parameter to look for optimization.
Key configurations:
- Enable dynamic allocation by default while running in a cluster for an efficient use of the idle nodes
- Make sure to have enough executor memory per core
(executor-memory / no.of cores) > per partition data size
// But not at all times, depends on your data and your code- Just increasing no.of executors doesn’t guarantee speed
(no.of executors * no.of cores) is the parallelism- Serialization and compression helps while we shuffle or persist the block of data. Use ‘Kryo’ serialization and enable compression by default.
spark.sql.shuffle.partitionsis used when shuffling data for joins or aggregations. Hence use the desired parallelism based on your data (default is 200, which is very less for big data)
Conclusion
Though Spark is very popular and prominent Big Data processing engine — optimization is always a challenging topic. Hence, it is very important to understand the underlying data and all possible spark configurations for your process.
There’s no silver bullet in configuring Spark parameters for any process. It all depends on your data as well as code. Be advised to perform different benchmarks before deciding on the optimization technique for your program.
HAPPY LEARNING 😊😊😊



Comments
Post a Comment